Which of the Following Statements Best Describes Apache Spark
To read a CSV file you must first create a DataFrameReader and set a number of options. Spark can round on Hadoop standalone or in the cloud.
1
Which of the following statements about Dataframes in Spark isare true.
. Spark SQL supports the following Data Definition Statements. It is an immutable distributed collection of data. It is much faster than MapReduce for complex applications.
1 Introduction 2 Introduction To. Consider the following statement is the correct context of Apache Spark. It runs on Hadoop clusters with RAM drives configured on each DataNode.
Which of the following statements BEST describes the stork. Spark interoperates only with Hadoop C. It was originally developed at UC Berkeley.
1 What is Apache Spark. Features of Apache Spark. MapReduce processes data in batches only.
The correct answer is E as in Apache Spark all transformations are evaluated lazily and all the actions are evaluated eagerly. Question 9 Which of the following statements about the Spark driver is incorrect. It delivers speed by providing in-memory computation capability.
Apache Spark is easy to use and flexible data processing framework. Which of the following are options when creating a Virtual Warehouse. Abraham Silberschatz Professor Henry F.
Click card to see definition. Spark runs almost 100 times faster than. It basically designed for fast computation and developed at UC Berkeley in 2009.
Specifies a result set producing statement and may be one of the following. It was donated to Apache software foundation in 2013 and now Apache Spark has become a top level Apache project from Feb-2014. Which statement about Apache Spark is true.
This Apache Spark Quiz is designed to test your Spark knowledge. Apache Spark has following. The questions asked at a big data developer or Apache spark developer job interview may fall into one of the following.
Spark is an Apache. A Dataframe is a collection of data organized into. In this case the only command that will be evaluated.
It can handle both batch and real-time. Spark enables Apache Hive users to run their unmodified queries much faster B. Top 50 Spark Interview Questions and Answers for 2021.
Spark allows you to choose whether you want to persist Resilient Distributed. Tap card to see definition. Apache Spark provides faster and more general data processing platform engine.
Spark is a popular data. According to Databricks definition Apache Spark is a lightning-fast unified analytics engine for big data and machine learning. Apache Spark is an open source parallel processing framework for running large-scale data analytics applications across clustered computers.
At ProgramsBuzz you can learn share and grow with millions of techie around the world from different domain like Data Science Software Development QA and Digital Marketing. The warehouse cache may be. The Spark driver is the node in which the Spark applications main method runs to.
Point out the correct statement. QUERY This clause is optional and may be omitted. It contains frequently asked Spark multiple choice questions along with a detailed explanation of their answers.
Spark processes data in batches as well as in real-time. Place one foot on the inside of the leg raise. All the functionalities being provided by Apache Spark are built on the highest of the Spark Core.
Dfsparkreadformat csvoption headertrueload filePath Here we load a CSV.
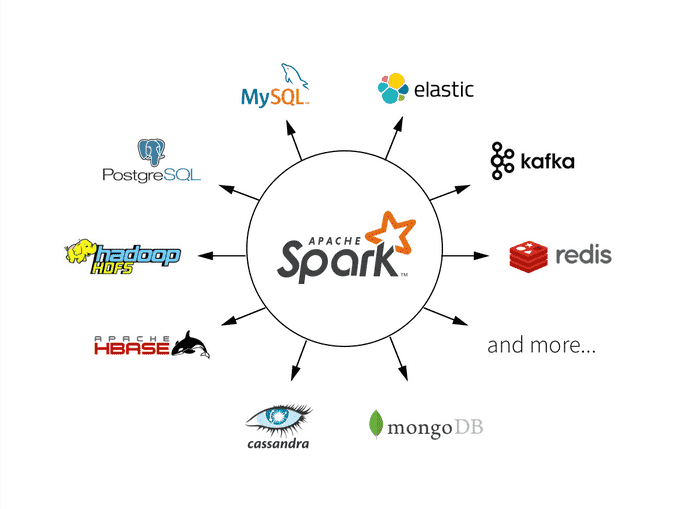
Apache Spark What Is Spark
Sparks
1
Fire
No comments for "Which of the Following Statements Best Describes Apache Spark"
Post a Comment